티스토리 뷰
ℹ️요약
- 이미지의 크기를 고정(600x600)시킨다.
- 해당 객체에 대한 bounding Box를 잘라 객채별로 분류한다.
- 잘라진 이미지 크기(224x224)를 변형한다.
- vgg16(backbone)의 입력값을 224x224로 변경한다.
- faster-rcnn을 통해 학습을 수행한다.
0. Abstract
- 학습 검출기로는 데이터 분류가 가능하나 가시적인 공개 데이터 셋에 대해서 효능적인 성능을 내지 못하는 문제가 있다.
- 이에 따라 본 논문에서는 X-ray를 위한 물체 검출 알고리즘을 제안한다.
- X-ray 물체를 이미제에서의 객체 및 색상을 기반으로 하는 전경-배경 분할 알고리즘을 사용한다.
- 그 후 해당 객체를 각각의 유형의 개체로 분류하고 개요를 설명한다.
- 학습 알고리즘은 Faster R-CNN을 사용한다.
1. Introduction
- 본 논문에서는 X-ray 영상에서 검출된 물체의 모든 클레스를 아웃라인으로 표시하기 위한 전경-배경 분할 방법을 제안한다.
- 해당 방법을 통해 불필요한 X-ray 영상 정보를 제거 할 수 있다.
- 그 후, 감지된 물체만 접촉하는 이미지를 CNN을 통해 확인한다.
- 논문의 구성은 다음과 같이 묘사된다.
- Section 2(Related Work) : 관련 작업(학습모델)에 대한 전반적인 배경 소개를 한다.
- Section 3(Foreground-Background Segmentation) : 전경-배경 분할 방법을 상세히 제시한다.
- Section 4(Object Detection) : 학습-결과에 대해 인식율에 대해 설명한다.
- Section 5(Conclusion) : 마무리 및 종합결과에 대해 설명한다.
2. Related Work
- 학습을 위해 CNN을 도입한다.
- 모델 종류는 다음과 같다.
- SW-CNN
- Fast-RCNN
- Faster-RCNN → 가장좋기 때문에 해당 모델로만 비교한다.
- F-FCNN
- YOLO-v2
3. Foreground-Background Segmentation
- 서두
- X-ray에서 검출된 영상의 물체는 수화물 전체이다.
- 그러나 입력 부분 특정영역만 검출할 영역이 일부 물체를 포함하고 있으며, 나머지 물체는 배경(책가방, 가죽끈 등) 불필요한 영역이다.
- 하지만 해당 영역에 대한 정보가 영상에 많은 부분을 차지한다.
- 본문
- 검출기에서 입력된 모든 영상의 크기를 600x600으로 크기를 조절한다.
- 이미지의 형상은 vgg16에 의해 추출한다.
- 문제점
- 열쇠와 같이 작은 물체는 1~2 pixel만 유지되거나 완성되지 않을 수 있다.
- 작은 물체에 대한 식별율이 하락 한다.
- 밀도가 큰 물체는 밀도가 낮은 물체보다 어둡게 묘사된다.
- ex> 회로 기판, 배터리, 우산, 열쇠 그리고 밀도가 다른 몇몇 병들은 금속으로 만들어져 있다.
- 이에 따라 새로운 색상 기반 **전경-배경 분할 알고리즘**을 제안한다.
- 색상에 대한 기준은 6가지 물체 색상 분포를 가지고 있다.
- Red : 224~255
- Green : 216~255
- Blue : 201~255
- 이미지의 일부가 임계값에 속한다면 배경이고 그렇지 않다면 배경이 아닌것으로 간주한다.
- 전경-배경 분할방법의 신뢰성 검증을 위해 32,253개의 정제된 이미지와 비교한다.
4 Object Detection
- 서두
- 데이터 시트에 6가지 유형의 개채를 분류한다.
- power bank : 2,384
- laptop : 1,395
- bottle : 7,171
- mobile phone : 9,540
- keys : 11,765
- umbrella : 7,574
- others(background)
- 데이터 전처리 단계에서 색상 기반 전경-배경 분할 방법을 도입한다.
- vgg16를 이용한 faster-rcnn와 결합할 것을 제안한다.
- 데이터 시트에 6가지 유형의 개채를 분류한다.
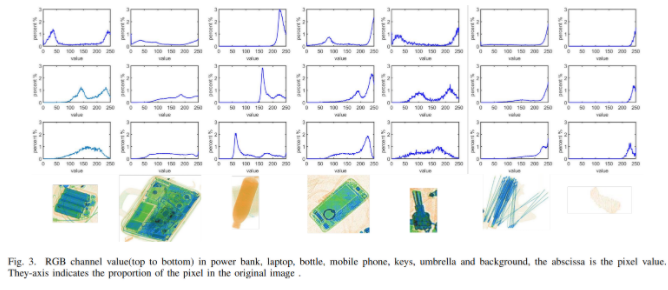
- 본문 1
- X-ray 수하물의 이미지는 조명, 질감 및 색상 정보가 다르며, 해당 사진은 내부 구조(틀)만 담겨져 있을 뿐 재료(물성)에 따라 다른색으로 표기되어 있다.
- X-ray의 해당 동일물체에 대해서 특징점 또한 다름을 알 수 있으며 해당 데이터 시트에 대해 목표량을 달성하기 어렵다.
- 이를 해결하기 위해 입력 이미지를 데이터에서 각각 bBox로 잘라내고, 해당 이미지 크기를 224x224로 입력값이 구성된 vgg16 네트워크를 설계한다.

- 본문 2
- 학습 데이터 비율 정의는 다음과 같다.
- train : 25%
- validation : 25%
- test : 50%
- 학습 데이터 셋 강화를 위한 수행작업은 다음과 같다.
- random flipping
- random cropping
- rotation
- 파라메터 구성은 다음과 같다.
- gradient descent : SGD
- momentum : 0.9
- weight decay : 0.0005
- learning rate : 0.001
- divide step : 10
- 전경-배경 분할 알고리즘을 통해 개선된 모델이다.
- 학습 데이터 비율 정의는 다음과 같다.

- 개선
- AP를 통해 데이터를 평가하며, Detector와 Backbone을 통한 결과는 다음과 같다.

5. Conclusion
- 색상 정보를 기반으로 한 전경-배경 분할 방법을 제안한다.
- 해당 방법을 통해 Faster-RCNN의 Backbone인 vgg16을 수정한다.
- 수정된 모델을 통해 학습을 수행한다.
❓생각정리
- 전체적으로 물건이 겹침현상에 따라 물성 분석이 진할경우 해당 물채는 어떻게 식별할 수 있을까?
- 특정 상황에 대한 고려점을 기준으로 두었을때 물체의 혼잡도(겹침의 정도)는 어느정도여야 하는가?
- 예를 들어 밀도가 높은 물체(여행가방에 물품)가 많을 경우는 해당 논문의 방법이 적합한 방법인가?
- 밀도가 높은 일반 가방품목일 경우 어떻게 인식결과가 추출될까?
❗ 결론
- 여행가방이 아닌 일반 품목 가방일 경우 해당 물품을 인식한 것은 가능할 것이다.
반응형
'Record > AI' 카테고리의 다른 글
| [인공지능] 논문 리뷰(The Good, the Bad and the Ugly Evaluating) (0) | 2022.05.10 |
|---|---|
| [인공지능] X-ray 관련 학습 데이터 링크 (0) | 2022.05.10 |
| [인공지능] Pytorch Object Detection Fintuning Tutorial 2 (0) | 2022.05.09 |
| [인공지능] Pytorch Object Detection Fintuning Tutorial 1 (0) | 2022.05.09 |
| [인공지능] Pytorch Tensorboard (0) | 2022.05.09 |
댓글
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- faiss
- image noise
- 이미지 잡음
- Example
- X-ray Dataset
- X-ray 합성
- pytest
- cascade Mask R-CNN
- Prototype
- 연관 이미지 검색
- torchvision
- gitmoji
- C#
- segment anything
- pytorch
- 산업용
- GD Xray
- OPI Xray
- SI Xray
- Filter
- 16bit 합성
- X-RAY
- 인공지능
- fastapi
- Ai
- Python
- ROI
- React Redux
- REACT
- 산업용 X-Ray
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
글 보관함